RULEST → CONCENTRATOR → RANKER
Fully automated hashcat rule generation pipeline: extract candidate rules with rulest, deduplicate and normalise with concentrator, then score & sort by real-world value with ranker. Supports both MAB (default) and legacy exhaustive ranking.
Prefer clicking over typing? The pipeline also ships as a desktop GUI — pick your wordlists,
choose a mode preset or dial in custom parameters, select your OpenCL device, and watch
coloured live output as rulest → concentrator → ranker run end to end.
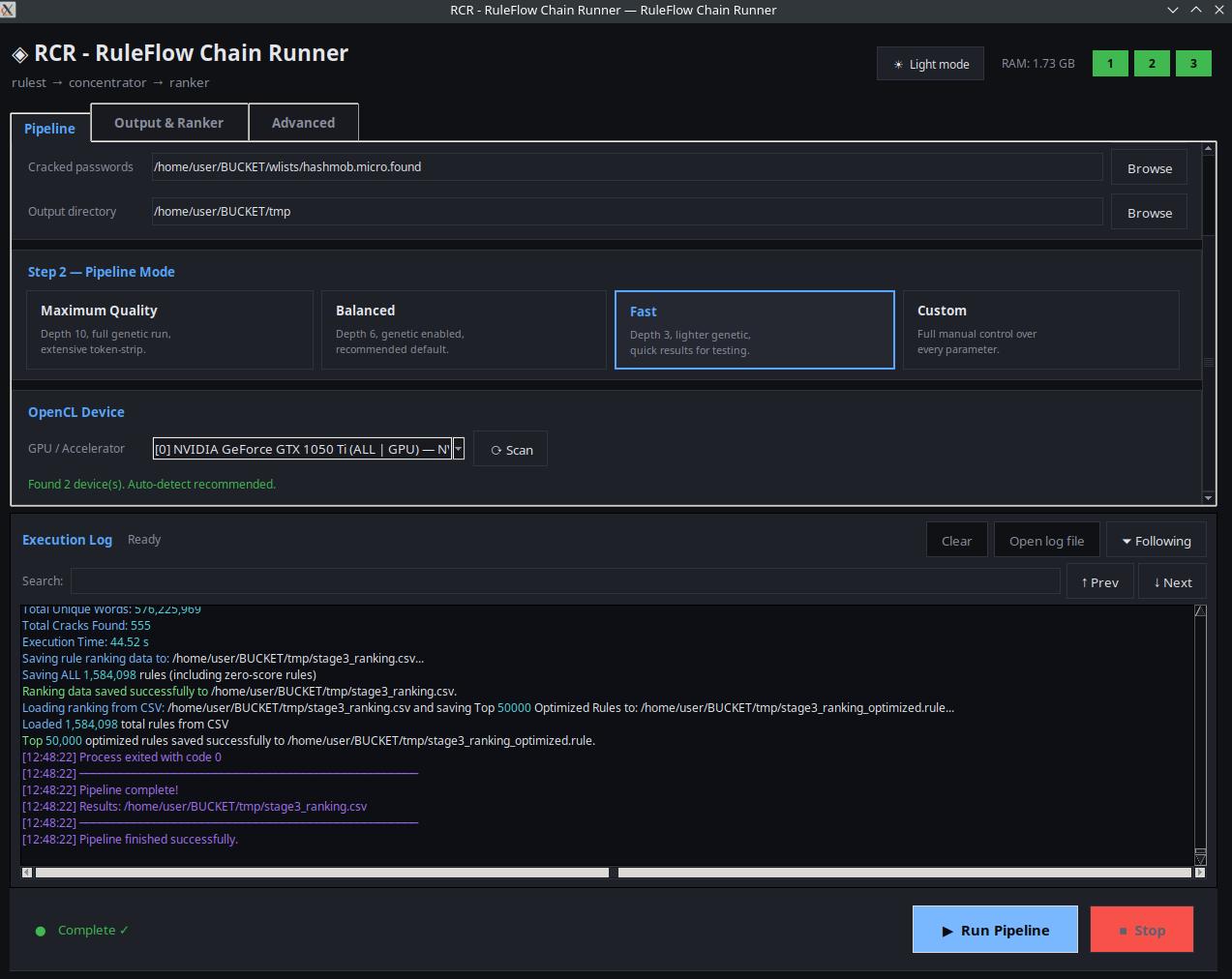
RuleFlow GUI mid-run — legacy ranker mode, NVIDIA GTX 1050 Ti selected, pipeline completed successfully.
Copy the entire script below and run it on your machine.
It automatically checks for and offers to download missing scripts (rulest_v2.py, concentrator.py, ranker.py), verifies required Python packages (numpy, pyopencl, tqdm, psutil) with optional auto-install, then prompts for wordlists and lets you choose mode and ranking strategy.
#!/bin/bash
# =============================================================================
# INTERACTIVE HASHCAT RULE PIPELINE 2026
# =============================================================================
echo -e "\033[1;36m"
echo "╔════════════════════════════════════════════════════════════════╗"
echo "║ INTERACTIVE HASHCAT RULE PIPELINE ║"
echo "╚════════════════════════════════════════════════════════════════╝"
echo -e "\033[0m"
# ====================== DEPENDENCY CHECK ======================
echo -e "\n\033[1;33m=== Checking Required Scripts ===\033[0m"
MISSING=()
if [ ! -f "rulest_v2.py" ]; then MISSING+=("rulest_v2.py"); fi
if [ ! -f "concentrator.py" ]; then MISSING+=("concentrator.py"); fi
if [ ! -f "ranker.py" ]; then MISSING+=("ranker.py"); fi
if [ ${#MISSING[@]} -gt 0 ]; then
echo -e "\033[1;31mMissing scripts: ${MISSING[*]}\033[0m"
read -p "Download missing scripts? (y/n): " CONFIRM_DL
if [[ "$CONFIRM_DL" =~ ^[Yy]$ ]]; then
for script in "${MISSING[@]}"; do
case "$script" in
rulest_v2.py) URL="https://raw.githubusercontent.com/A113L/rulest/refs/heads/main/rulest_v2.py" ;;
concentrator.py) URL="https://raw.githubusercontent.com/A113L/concentrator/refs/heads/main/concentrator.py" ;;
ranker.py) URL="https://raw.githubusercontent.com/A113L/ranker/refs/heads/main/ranker.py" ;;
esac
echo -e "\033[1;34mDownloading $script...\033[0m"
wget -q --show-progress "$URL" -O "$script" && echo -e "\033[1;32m✓ $script OK\033[0m" || exit 1
done
else
echo -e "\033[1;31mCannot continue.\033[0m"
exit 1
fi
else
echo -e "\033[1;32mAll scripts present.\033[0m"
fi
# ====================== PYTHON PACKAGE CHECK ======================
echo -e "\n\033[1;33m=== Checking Python Dependencies ===\033[0m"
PYTHON_CMD=""
for cmd in python3 python; do
if command -v "$cmd" &>/dev/null; then
PYTHON_CMD="$cmd"
break
fi
done
if [ -z "$PYTHON_CMD" ]; then
echo -e "\033[1;31mError: No Python interpreter found. Please install Python 3.\033[0m"
exit 1
fi
echo -e "\033[1;34mUsing: $($PYTHON_CMD --version 2>&1)\033[0m"
REQUIRED_PACKAGES=("numpy" "pyopencl" "tqdm" "psutil")
MISSING_PACKAGES=()
for pkg in "${REQUIRED_PACKAGES[@]}"; do
if ! $PYTHON_CMD -c "import $pkg" &>/dev/null; then
MISSING_PACKAGES+=("$pkg")
echo -e "\033[1;31m✗ $pkg — not found\033[0m"
else
echo -e "\033[1;32m✓ $pkg — OK\033[0m"
fi
done
if [ ${#MISSING_PACKAGES[@]} -gt 0 ]; then
echo -e "\n\033[1;33mMissing packages: ${MISSING_PACKAGES[*]}\033[0m"
read -p "Install missing packages now? (y/n): " CONFIRM_PIP
if [[ "$CONFIRM_PIP" =~ ^[Yy]$ ]]; then
# Detect pip
PIP_CMD=""
for cmd in pip3 pip "$PYTHON_CMD -m pip"; do
if $cmd --version &>/dev/null 2>&1; then
PIP_CMD="$cmd"
break
fi
done
if [ -z "$PIP_CMD" ]; then
echo -e "\033[1;31mError: pip not found. Install pip and retry.\033[0m"
exit 1
fi
for pkg in "${MISSING_PACKAGES[@]}"; do
echo -e "\033[1;34mInstalling $pkg...\033[0m"
if $PIP_CMD install "$pkg" --quiet --progress-bar on; then
echo -e "\033[1;32m✓ $pkg installed successfully\033[0m"
else
echo -e "\033[1;31mFailed to install $pkg. Try manually: $PIP_CMD install $pkg\033[0m"
exit 1
fi
done
# Verify installs
echo -e "\n\033[1;34mVerifying installations...\033[0m"
for pkg in "${MISSING_PACKAGES[@]}"; do
if $PYTHON_CMD -c "import $pkg" &>/dev/null; then
echo -e "\033[1;32m✓ $pkg — verified\033[0m"
else
echo -e "\033[1;31m✗ $pkg — verification failed! Aborting.\033[0m"
exit 1
fi
done
else
echo -e "\033[1;31mCannot continue without required packages.\033[0m"
exit 1
fi
else
echo -e "\033[1;32mAll Python packages present.\033[0m"
fi
# ====================== INPUT FILES ======================
echo -e "\n\033[1;33m=== Step 1: Input Files ===\033[0m"
read -p "Base wordlist path: " BASE_WORDLIST
read -p "Target wordlist path: " TARGET_WORDLIST
read -p "Cracked passwords list: " CRACKED_LIST
for f in "$BASE_WORDLIST" "$TARGET_WORDLIST" "$CRACKED_LIST"; do
[ ! -f "$f" ] && { echo -e "\033[1;31mError: $f not found!\033[0m"; exit 1; }
done
# ====================== MODE SELECTION ======================
echo -e "\n\033[1;33m=== Step 2: Pipeline Mode ===\033[0m"
echo "1) Maximum Quality"
echo "2) Balanced (Recommended)"
echo "3) Fast & Light"
echo "4) Custom"
read -p "Select mode (1-4) [2]: " MODE_CHOICE
MODE_CHOICE=${MODE_CHOICE:-2}
case $MODE_CHOICE in
1) MODE="maximum" ;;
2) MODE="balanced" ;;
3) MODE="fast" ;;
4) MODE="custom" ;;
*) MODE="balanced" ;;
esac
# ====================== LEGACY MODE ======================
echo -e "\n\033[1;33m=== Step 3: Ranking Mode ===\033[0m"
read -p "Use legacy (exhaustive) ranker mode? (y/n) [n]: " LEGACY_CHOICE
LEGACY_CHOICE=${LEGACY_CHOICE,,}
# ====================== DEFAULT PARAMETERS ======================
DEPTH=6
GEN_GENERATIONS=300
GENETIC_POP=600
BLOOM_MB=800
STAGE0_PROCESSES=0
TOKEN_STRIP_MAX_PREFIX=6
TOKEN_STRIP_MAX_SUFFIX=6
TOKEN_STRIP_CHUNK_SIZE=0
# Target Hours per mode
case $MODE in
maximum) TARGET_HOURS=2.0 ;;
balanced) TARGET_HOURS=1.0 ;;
fast) TARGET_HOURS=0.5 ;;
*) TARGET_HOURS=1.5 ;;
esac
# Ranker defaults
case $MODE in
maximum)
RANKER_K=50000
RANKER_MAB_SCREENING=5
RANKER_MAB_FINAL=10
RANKER_PRESET="high_memory" ;;
balanced)
RANKER_K=25000
RANKER_MAB_SCREENING=4
RANKER_MAB_FINAL=8
RANKER_PRESET="medium_memory" ;;
fast)
RANKER_K=12000
RANKER_MAB_SCREENING=3
RANKER_MAB_FINAL=5
RANKER_PRESET="low_memory" ;;
*)
RANKER_K=25000
RANKER_MAB_SCREENING=4
RANKER_MAB_FINAL=8
RANKER_PRESET="medium_memory" ;;
esac
# ====================== ADVANCED CONFIGURATION ======================
echo -e "\n\033[1;33m=== Advanced Configuration ===\033[0m"
read -p "Customize parameters (depth, strip, etc.)? (y/n) [y]: " CUSTOMIZE
CUSTOMIZE=${CUSTOMIZE:-y}
if [[ "$CUSTOMIZE" =~ ^[Yy]$ ]]; then
echo -e "\n\033[1;36m--- Rulest Core Settings ---\033[0m"
read -p "Max Depth ($DEPTH): " tmp; [ -n "$tmp" ] && DEPTH=$tmp
read -p "Genetic Generations ($GEN_GENERATIONS): " tmp; [ -n "$tmp" ] && GEN_GENERATIONS=$tmp
read -p "Genetic Population ($GENETIC_POP): " tmp; [ -n "$tmp" ] && GENETIC_POP=$tmp
read -p "Target Hours ($TARGET_HOURS): " tmp; [ -n "$tmp" ] && TARGET_HOURS=$tmp
echo -e "\n\033[1;36m--- Token Strip Settings ---\033[0m"
read -p "Max Prefix Length ($TOKEN_STRIP_MAX_PREFIX): " tmp; [ -n "$tmp" ] && TOKEN_STRIP_MAX_PREFIX=$tmp
read -p "Max Suffix Length ($TOKEN_STRIP_MAX_SUFFIX): " tmp; [ -n "$tmp" ] && TOKEN_STRIP_MAX_SUFFIX=$tmp
read -p "Chunk Size (0=auto) ($TOKEN_STRIP_CHUNK_SIZE): " tmp; [ -n "$tmp" ] && TOKEN_STRIP_CHUNK_SIZE=$tmp
echo -e "\n\033[1;36m--- Other Settings ---\033[0m"
read -p "Bloom Filter (MB) ($BLOOM_MB): " tmp; [ -n "$tmp" ] && BLOOM_MB=$tmp
read -p "Stage 0 Processes (0=auto) ($STAGE0_PROCESSES): " tmp; [ -n "$tmp" ] && STAGE0_PROCESSES=$tmp
# Ranker settings
echo -e "\n\033[1;36m--- Ranker Settings ---\033[0m"
read -p "Final top rules to keep ($RANKER_K): " tmp; [ -n "$tmp" ] && RANKER_K=$tmp
if [[ "$LEGACY_CHOICE" != "y" ]]; then
read -p "MAB Screening Trials ($RANKER_MAB_SCREENING): " tmp; [ -n "$tmp" ] && RANKER_MAB_SCREENING=$tmp
read -p "MAB Final Trials ($RANKER_MAB_FINAL): " tmp; [ -n "$tmp" ] && RANKER_MAB_FINAL=$tmp
fi
fi
# ====================== EXECUTION ======================
echo -e "\n\033[1;32mStarting $MODE mode → Target: ${TARGET_HOURS}h | Depth: $DEPTH | Prefix/Suffix: $TOKEN_STRIP_MAX_PREFIX/$TOKEN_STRIP_MAX_SUFFIX | Chunk: ${TOKEN_STRIP_CHUNK_SIZE:-auto}\033[0m"
# 1. Rulest
echo -e "\n\033[1;34m[1/3] Running Rulest...\033[0m"
$PYTHON_CMD rulest_v2.py "$BASE_WORDLIST" "$TARGET_WORDLIST" \
-o stage1_raw.rule \
--max-depth $DEPTH \
--token-strip \
--genetic \
--genetic-generations $GEN_GENERATIONS \
--genetic-pop $GENETIC_POP \
--target-hours $TARGET_HOURS \
--bloom-mb $BLOOM_MB \
--token-strip-max-prefix $TOKEN_STRIP_MAX_PREFIX \
--token-strip-max-suffix $TOKEN_STRIP_MAX_SUFFIX \
--token-strip-chunk-size $TOKEN_STRIP_CHUNK_SIZE \
--token-strip-workers $STAGE0_PROCESSES
# 2. Concentrator
echo -e "\n\033[1;34m[2/3] Running Concentrator...\033[0m"
$PYTHON_CMD concentrator.py -p stage1_raw.rule --output_base_name stage2_cleaned --output-format line
CLEANED_RULE=$(ls stage2_cleaned*.rule 2>/dev/null | head -n 1)
[ -z "$CLEANED_RULE" ] && { echo -e "\033[1;31mError: Concentrator output not found!\033[0m"; exit 1; }
# 3. Ranker
echo -e "\n\033[1;34m[3/3] Running Ranker...\033[0m"
RANKER_CMD="$PYTHON_CMD ranker.py -w \"$BASE_WORDLIST\" -r \"$CLEANED_RULE\" -c \"$CRACKED_LIST\" -o stage3_ranking.csv -k $RANKER_K --preset $RANKER_PRESET"
if [[ "$LEGACY_CHOICE" == "y" ]]; then
RANKER_CMD="$RANKER_CMD --legacy"
else
RANKER_CMD="$RANKER_CMD --mab-screening-trials $RANKER_MAB_SCREENING --mab-final-trials $RANKER_MAB_FINAL"
fi
eval $RANKER_CMD
echo -e "\n\033[1;32mPipeline finished successfully!\033[0m"
echo -e "\033[1;32mResults → stage3_ranking.csv\033[0m"
rulest_v2.py, concentrator.py and ranker.py in the same directory (or in $PATH).
The script checks for all three tools and offers to download them automatically if missing. It also verifies Python packages (numpy, pyopencl, tqdm, psutil) and installs any that are absent.
A cracked password list (e.g., from a previous hashcat run) is required to rank rules.
Legacy mode exhaustively tests all rule–word combinations; MAB mode uses multi‑armed bandit for early elimination. The Customize prompt exposes depth, token-strip prefix/suffix/chunk, bloom filter, processes, and ranker settings.
1. Rulest – Extracts candidate transformation rules from the relationship between a base wordlist and a target wordlist. Uses token stripping, genetic algorithm and Bloom filter to keep memory usage low. Outputs stage1_raw.rule.
2. Concentrator – Deduplicates, normalises and optionally compresses the rule set. Runs in line mode, producing a clean, sorted rule list (stage2_cleaned_*.rule).
3. Ranker – Scores each rule against a cracked passwords list. Two modes:
- MAB (default) – Multi‑armed bandit with early elimination, fast and memory‑efficient.
- Legacy (exhaustive) – Tests every rule on every word, slower but deterministic.
Final output stage3_ranking.csv contains detailed statistics and stage3_ranking_optimized.rule contains the top -k rules with estimated crack rates, ready for use in hashcat.
⚡ Maximum Quality
- Rulest depth: 6 (configurable)
- Genetic gens: 300
- Ranker
-k 50000 - MAB screening/final: 5/10
- Preset: high_memory
⚖️ Balanced (default)
- Rulest depth: 6
- Genetic gens: 300
- Ranker
-k 25000 - MAB screening/final: 4/8
- Preset: medium_memory
Fast & Light lowers target hours to 0.5h, reduces genetic generations, uses -k 12000 with low_memory preset.
Custom mode lets you tweak every single parameter interactively — including TOKEN_STRIP_CHUNK_SIZE and stage‑0 workers — with MAB options hidden when legacy is chosen.
All modes share the same Customize prompt (default yes) which surfaces advanced settings.
- The script auto-detects your Python interpreter (
python3/python) and uses it throughout — no hardcodedpythoncalls. - Missing Python packages (
numpy,pyopencl,tqdm,psutil) are detected and installed automatically with your consent. - This pipeline relies on frequency and bandit ranking. Ideal when you want a fast, deterministic rule set.
- Provide a representative cracked list (at least a few thousand unique passwords) for meaningful scores.
- For large wordlists (>200 MB) increase
BLOOM_MB(e.g., 1600) to avoid false positives. - All intermediate files (
stage1_raw.rule,stage2_cleaned_*.rule) are kept – you can reuse them with other tools. - Legacy mode is much slower but guarantees full coverage; MAB is strongly recommended for large rule sets.